本文禁止转载,作者:的卢野地 yedi.online
1.环境配置
1.0环境选择
由于云服务器带宽不足以满足大数据集的传输,未使用第一次实验配置的云服务器环境,本次实验使用本地虚拟机的方式进行,使用hyper-v虚拟出Ubuntu虚拟机。
另外,在软件版本的选择上,我们放弃了第一次实验的古老版本(版本匹配问题太繁琐),尝试使用较新的版本并做好版本匹配,例如jdk17,hadoop3.3.1(至今为止的最新版本)。我们尝试把主要工作放在Hadoop、MapReduce的使用上,而简化环境配置的繁琐步骤,我们直接单机操作。
由于MapReduce是在Hadoop框架下的,所以需要安装Hadoop;又由于Hadoop依赖Java,我们需要安装JDK。
1.1JDK安装
这里安装最新版本的JDK,在Ubuntu环境下执行javac查得该机器中没有安装过,在给出的列表中选择最新的jdk17版本,如下图。
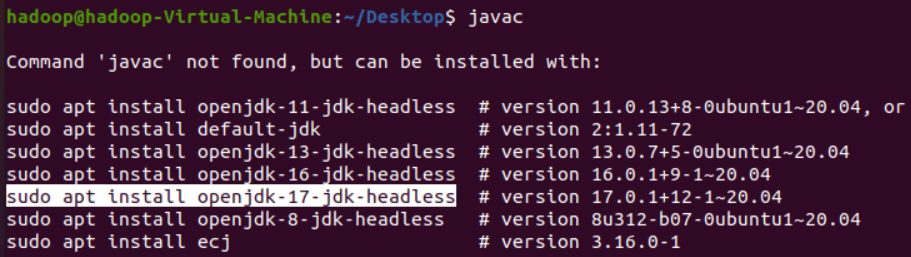
执行sudo apt install openjdk-17-jdk-headless。
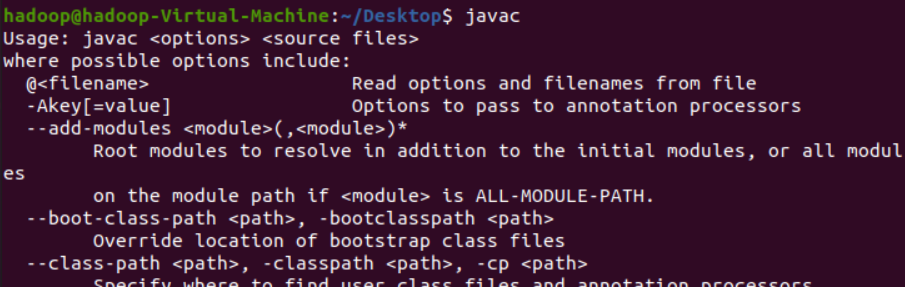
安装完成后,再次执行javac可以看到一系列使用帮助,说明成功安装,如下图。
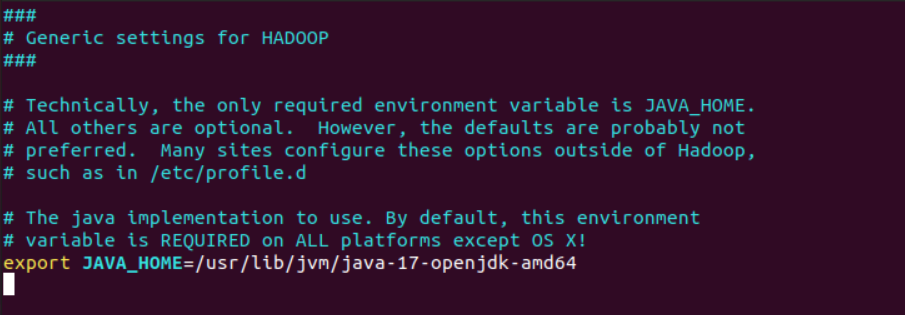
之后添加到环境变量,编辑/etc/profile,增加高亮的四行,如下图。
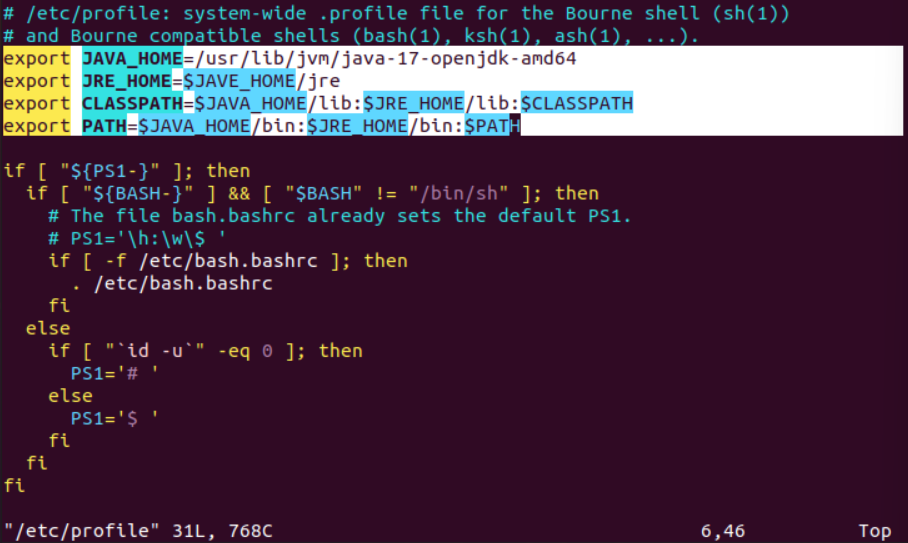
接着执行source /etc/profile使之生效。
1.2Hadoop安装
由于外网环境复杂多变,这里使用某大学镜像站下载hadoop-3.3.1。
执行wget https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.3.1/hadoop-3.3.1.tar.gz
很快,这不需要太长时间,即可以下载完成。
将其移动到/opt目录下,然后解压缩,如下图。

配置一些文件,主要修改的有如下图红圈标注的文件。
对于hadoop-env.sh需要配置一下JAVA_HOME。先使用echo JAVA_HOME命令查看查下路径,然后使用vim填写在相应位置处,如下两图。

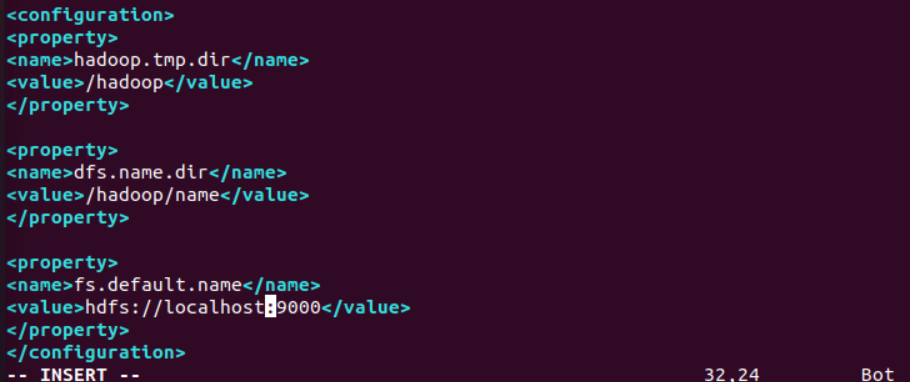
修改core-site.xml,如下图。
修改hdfs-site.xml,如下图。

修改mapred-site.xml,如下图。

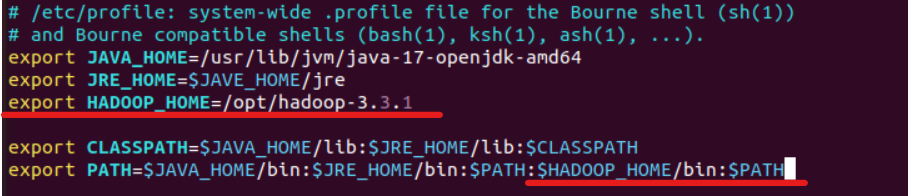
然后,还需要给Hadoop配置一下系统的环境变量。在/etc/profile中修改如下。
执行source /etc/profile使之生效,然后在任意目录下敲入hadoop得到一系列提示,说明hadoop环境变量配好了。
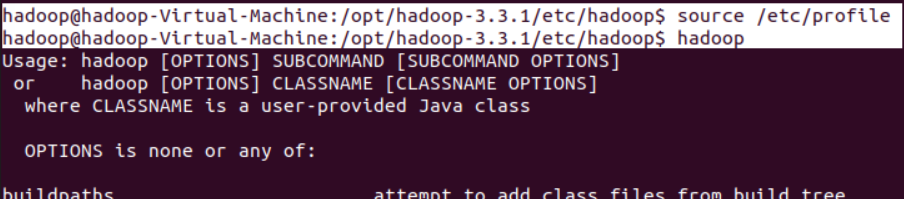
执行hadoop namenode -format初始化(仅在第一次运行前使用),唔,报错如下。

原因很可能是没有权限,因为/hadoop是要有根目录权限的,而我用的是hadoop用户,并非root。
于是尝试使用chown命令。在根目录新建一个hadoop文件夹,执行sudo chown -R hadoop /hadoop把/hadoop的所有权给hadoop用户。
重新执行hadoop namenode -format初始化。这样一来,namenode格式化成功了。
接下来在sbin目录下执行start-all.sh
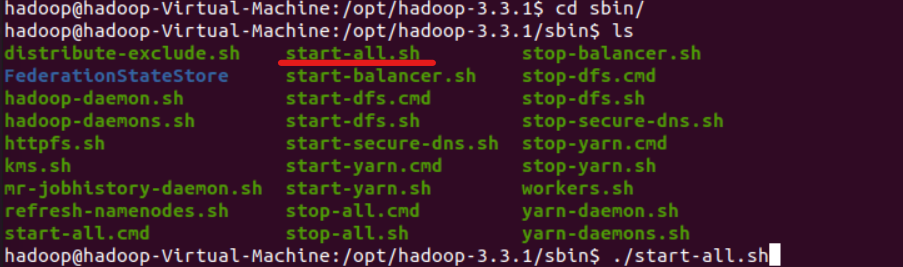
报错如下:
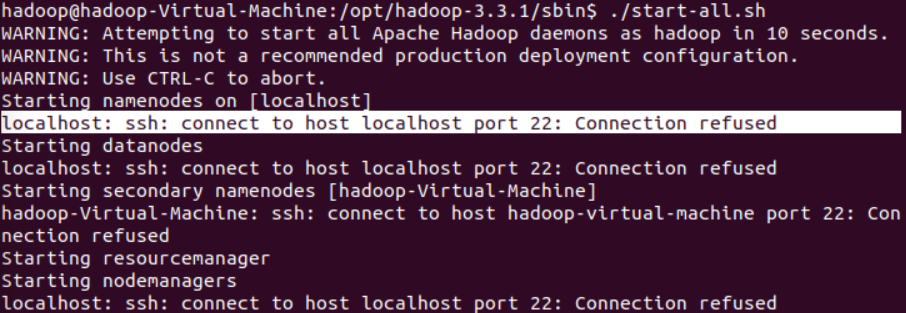
经过考虑,很可能没有安装ssh server,采用sudo apt-get install openssh-server来解决。
安装ssh后,重新执行./start-all.sh
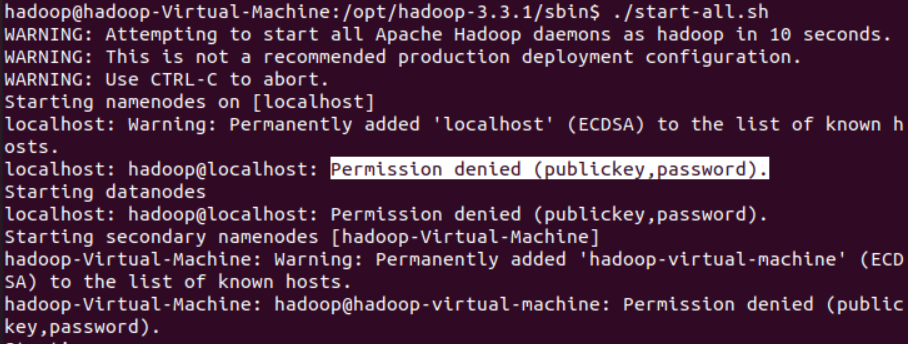
虽然没成功登录,但是大有进步,只是publickey password不对,为什么呢,因为还没有配置免密登录。
下面配置免密登录:
ssh-keygen然后一路按回车默认值。然后使用ssh-copy-id命令。
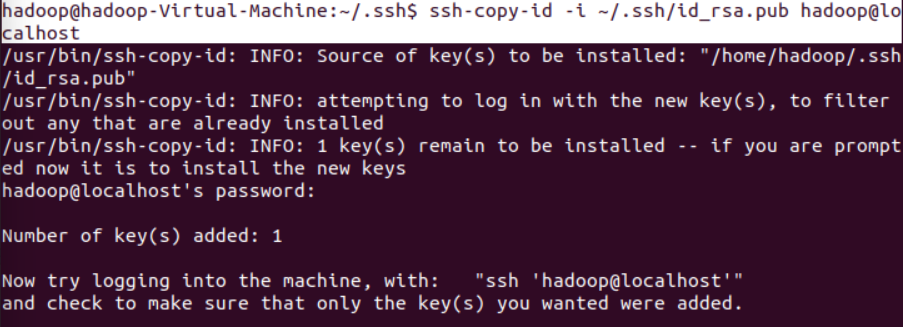
免密登录配置完成。
重新回到执行./start-all.sh的那一步。
没有报错,完美!
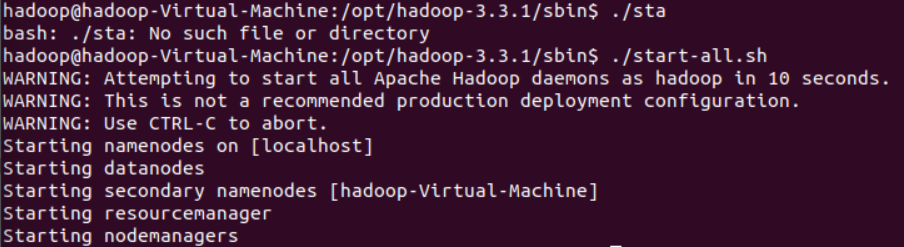
使用jps命令可以确认一下是否正常开起来了。

2.基于微博数据集的高频词统计
2.0数据集选取
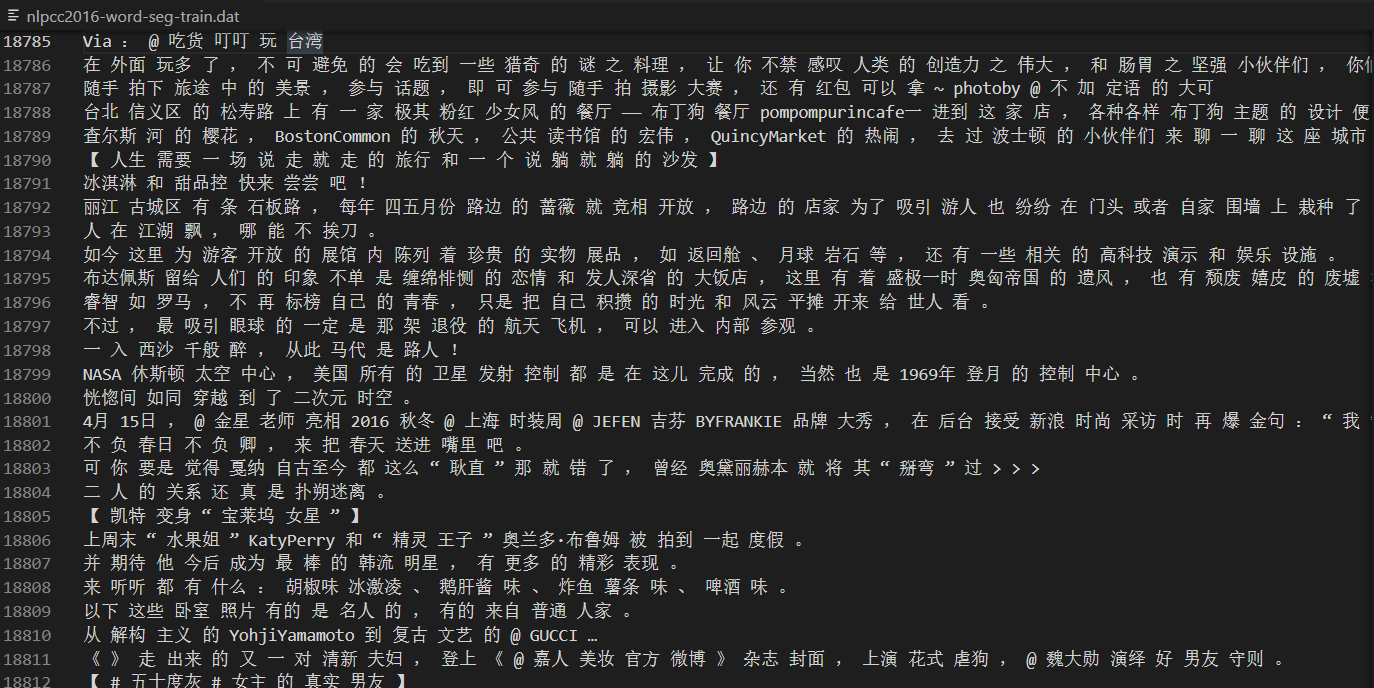
我们试图使用MapReduce进行数据集词语的统计。使用了Weibo分词数据集NLPCC2016分词赛道使用的数据集,该数据集由复旦大学根据新浪微博的数据标注生成,包含更多口语化的文本。该数据集包含经济,运动,环境等多种主题的语料。数据集地址:https://github.com/FudanNLP/NLPCC-WordSeg-Weibo。我们使用其中的训练数据集(已经分词了的数据),预览示意图如下(词语之间空格分割):
2.1建立目录
在hdfs中建立input目录,使用hadoop fs -mkdir /input命令。
并把数据文件放进去,hadoop fs -put /hadoop/file/nlpcc2016utf8.dat /input,即把数据集文件放到hdfs的input目录下。
如下图,操作后使用ls检查,确实放进去了。

2.2编写程序
参考了Hadoop官网的教程。
完整程序代码如下:
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}解释一下,这里分为map阶段和reduce阶段,分别对应TokenizerMapper和IntSumReducer。其中的map把各自的那一小部分中的词语计数进行统计,然后reduce阶段将它们进行汇总合并。
2.3编译打包
在在刚刚的代码中可以看到,这里的输入和输出的路径是从控制台中接收的参数。
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));在之前的环境变量等路径已经配置好的前提下,我们可以直接使用hadoop com.sun.tools.javac.Main WordCount.java语句进行打包。注意,2.2中代码的文件名为WordCount.java。
然后封装成一个jar包:jar cf wc.jar WordCount*.class

这里是到目前为止该项目文件夹中的所有文件,分别做一下解释:
nlpcc2016utf8.dat文件为数据集文件,此文件之后被放在了 hdfs里面的input目录。
WordCount.java文件为源代码文件,在这里面编写了map和reduce各自的功能。
三个class后缀名的文件为编译过程中产生的。
最终的wc.jar为封装为jar包的文件。
2.4提交执行
我们我们要提交给MapReduce去执行的,就是刚刚我们封装好的jar文件。
执行我们使用如下命令:
hadoop jar wc.jar WordCount /input /output
解解释一下,/input和/output为输入的参数对应代码中的args[0]、args[1]。
很快,map阶段结束了,在控制台可以看到如下输出:

接下来应该要开始reduce了,几秒后,reduce结束。

2.5执行结果
执行完成后会有一些对应信息的输出:
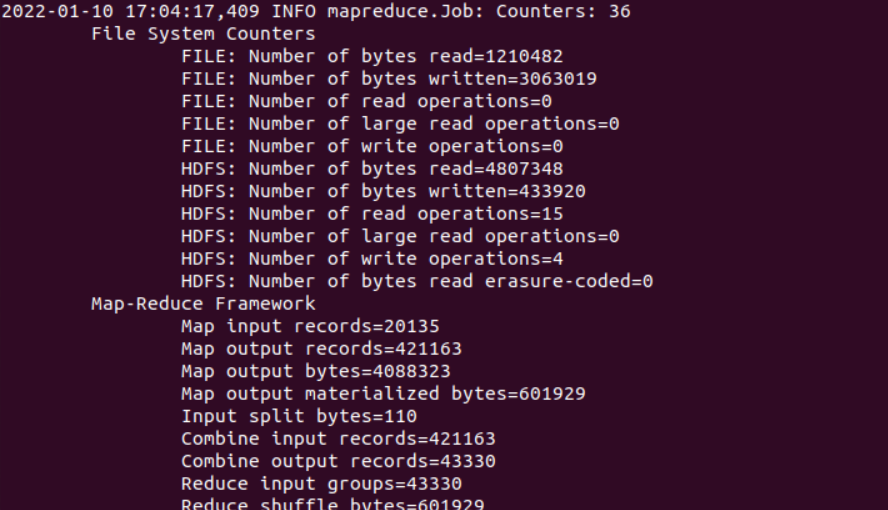
此外还会告诉我们有无错误。这里的error为0。
接下来,我们去/output目录查看一下。
使用hadoop fs -ls /output可以看到结果保存在part-r-00000中:

使用cat输出一下看看:
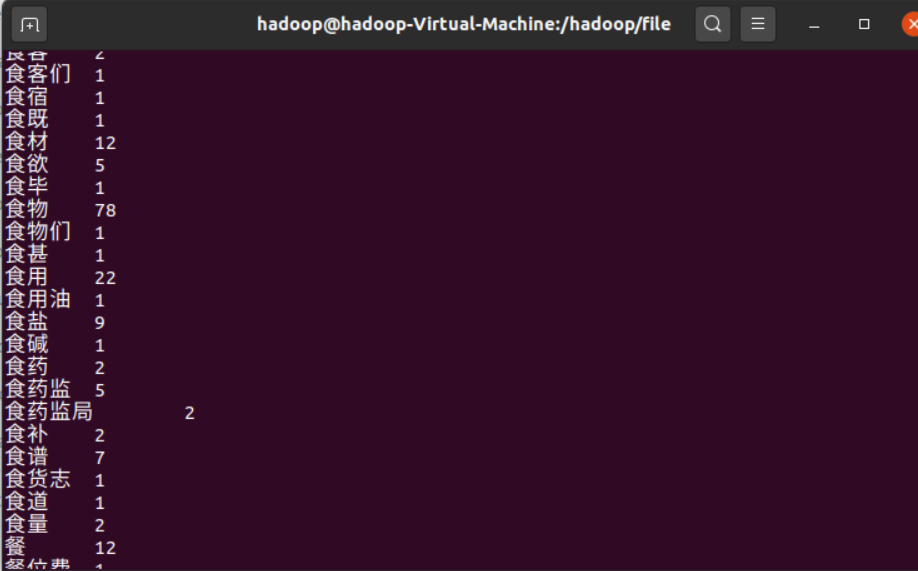
发现词语的排列顺序并非按照出现频次,还不能达到发现高频的目的。在改进中,我们设法排序,实现根据count排序。
接下来把此输出结果文件从hdfs中导出,使用hadoop fs -get xxx xxx,其中后两个参数分别为在hdfs中的文件路径和在计算机的文件系统中的文件路径。

3.一些改进
改进主要在两方面,一是使用MapReduce进行根据count的排序;二是增大数据集,现在的input只有一个数据集文件,我们希望增大数据集,以使用更多的map,体现MapReduce的优势。
3.1 根据频次排序
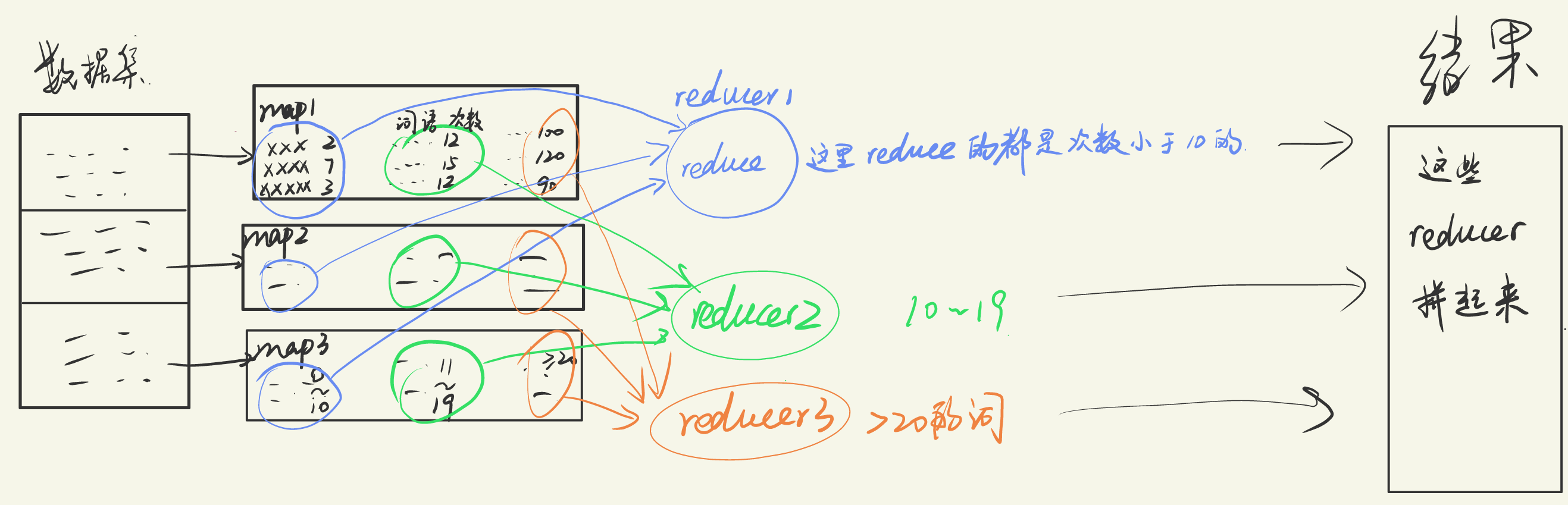
根据频次排序,那么也就是根据value进行排序。首先需要考虑的是在何时进行,是在map阶段之后进行交换键值然后就在此刻的每一个小部分里进行了排序,还是在reduce阶段之后进行。如果在map阶段之后就进行了交换,那么把key和value进行交换在reduce的时候,会不会因为原来value相同现在变成了key相同而被合并呢?如果在reduce以后再进行排序,那么会不会有可能造成数据量很大,这样的排序会是高效的吗,其实这样就相当于没有使用MapReduce进行排序,而只是进行了统计功能。
所以一定要在map阶段做一些事情,经过考虑,可以这样操作:
对于map的结果进行分块,比如出现次数0~19次的交给第一个reducer,出现10~19次的交给第二个reducer,更高的频次给第三个reducer。
示意图如下:
3.2 增大数据集使用更多map
数据集数据量较小原因是此数据集本来是作为自然语言处理的分词的训练数据集,其实我们可以在此训练数据集的基础上进行训练,然后对于更多的语句去进行分词,将预测的结果来作为我们再使用MapReduce来进行词频的统计的数据集。
4.可视化
查看一下结果,截图空间有限。
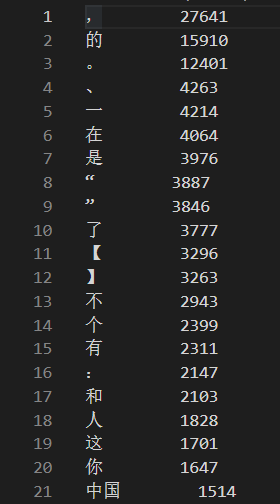
有大量数词冠词等类型的单字,还有例如“中国”等多字词语。我们分别进行展示,去除标点符号,单字与多字词各取最高频次的10个进行展示,做图如下。
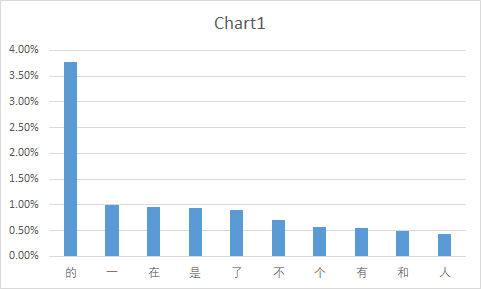
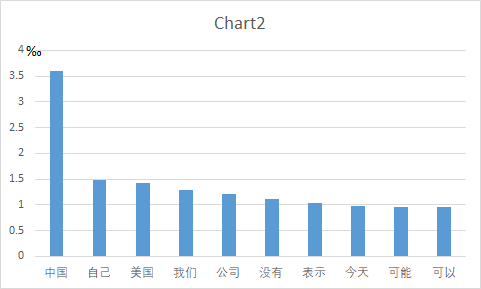
由于我们使用的数据集是为分词而设计的训练集,所以有对词语去重的可能,我们在此数据集上进行高频词语统计,可能结果与真实的微博数据略有偏差,且此结果可能与数据集采集时的社会背景等因素有关。